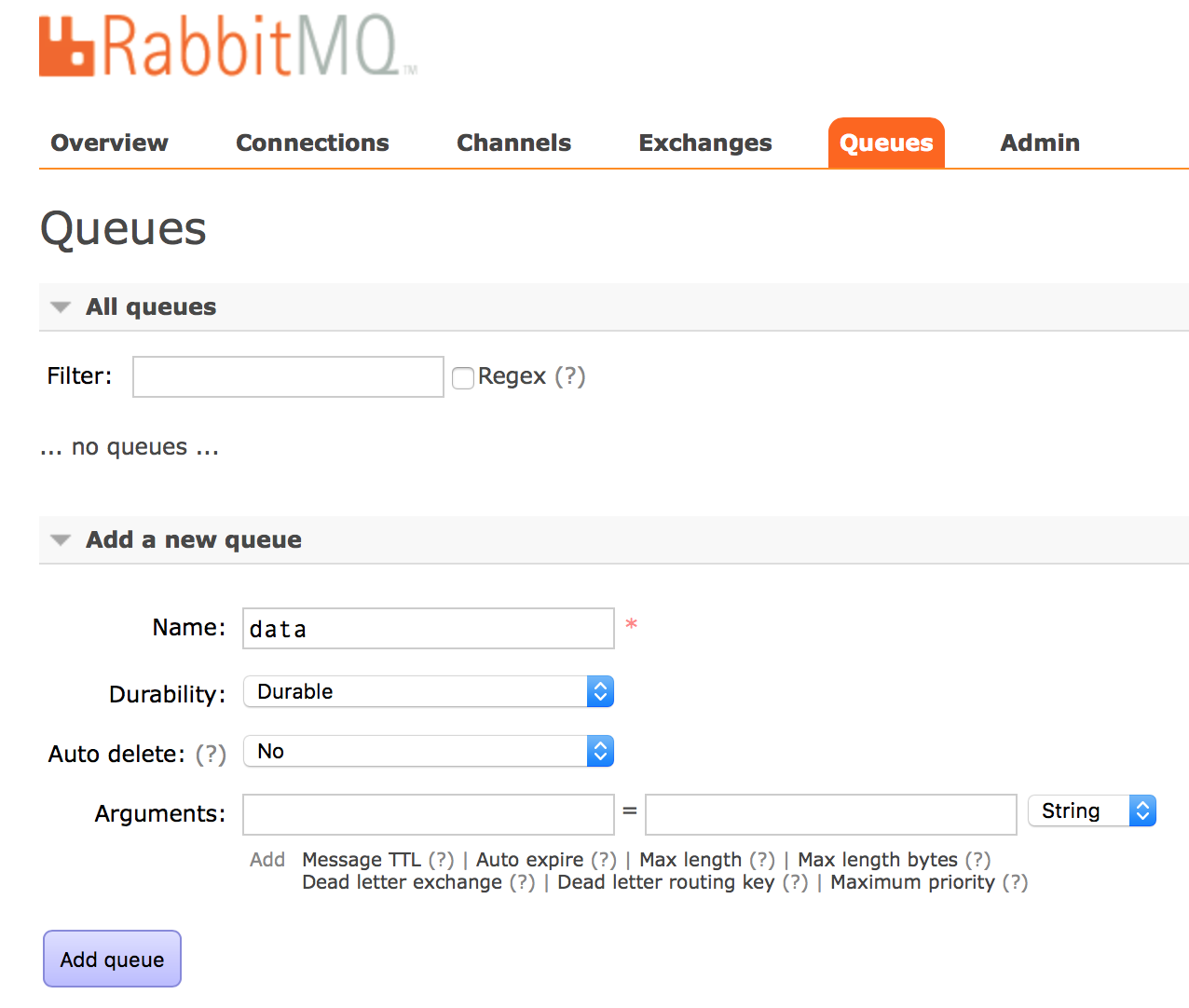
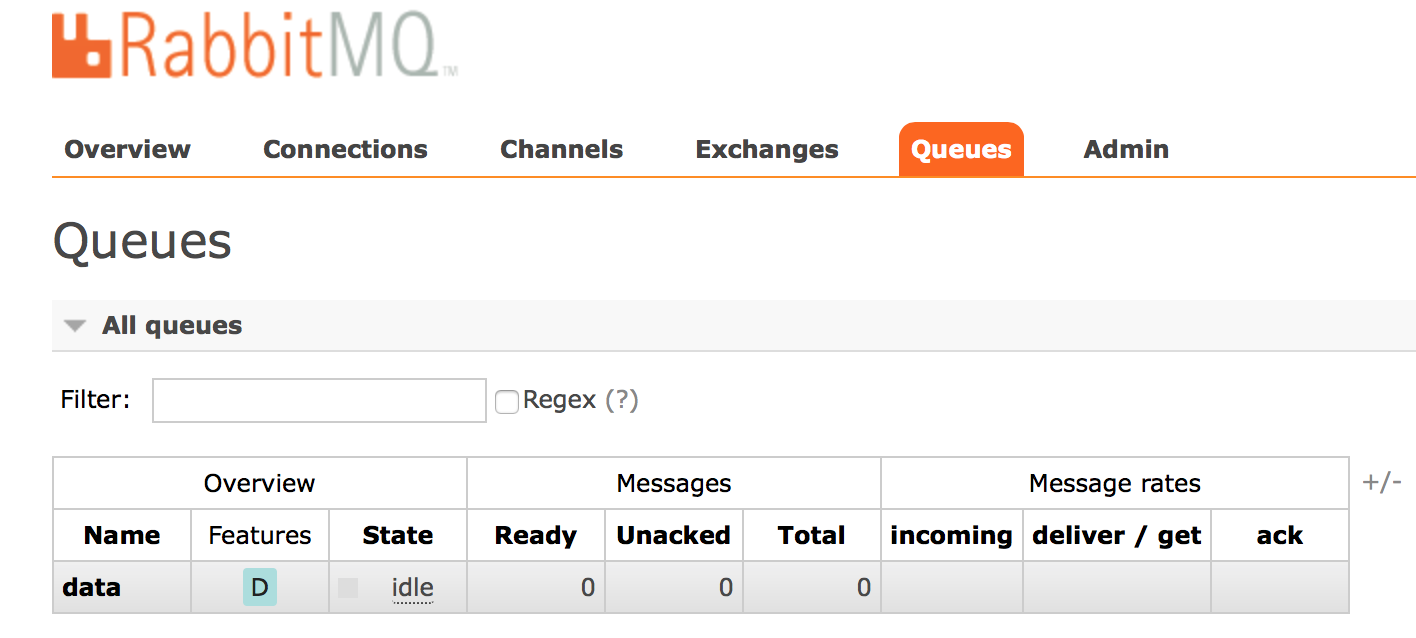
Este es otro post que quería compartir desde hace tiempo, entre otras cosas por su sencillez ya que en un proyecto anterior una solución de este tipo nos ayudó a resolver un problema puntual. Les pongo en contexto, debíamos desde nuestra empresa enviar una información que recabábamos diariamente, como es de suponer estábamos alejados fisicamente y en otra red y como no podía ser de otra forma no había permisos para por FTP o SSH hacer llegar la información, es por ello que dado las exigencias y con el poco tiempo que contábamos se nos ocurrió la idea «¿y si enviamos la información por email?» y así hicimos, construimos un pequeño programa Java el cual se ejecutaba periódicamente para enviar unos ficheros adjuntos que sacábamos diariamente.
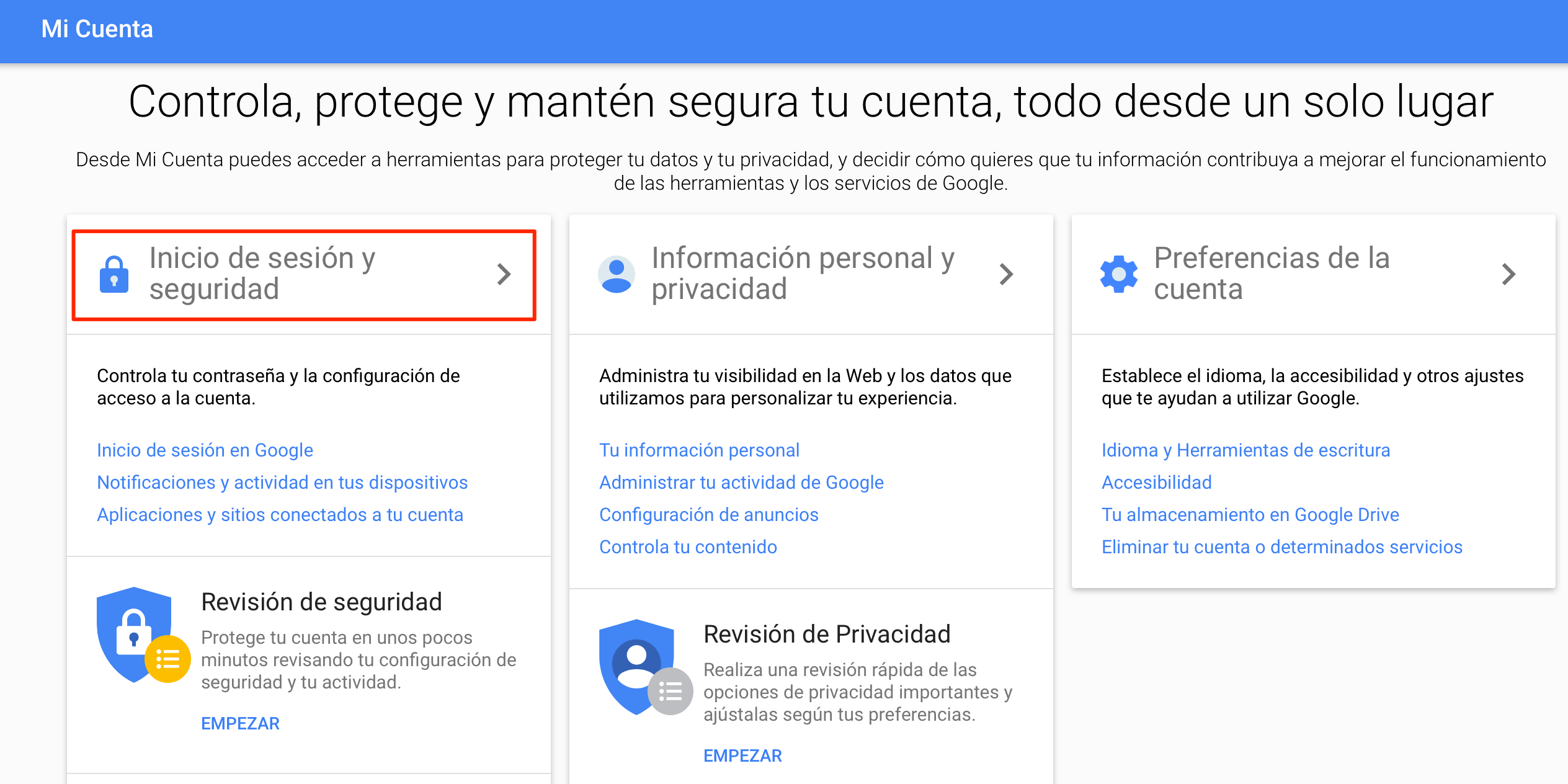
Primero que nada es necesario que desde la cuenta de GMAIL habilitemos el acceso de aplicaciones menos seguras. Para ello es necesario que ingresemos a nuestra cuenta de GMAIL y una vez dentro vayamos a la parte superior derecha donde este el icono de nuestra cuenta, hacemos clic en el icono y posteriormente al botón «Mi cuenta». Allí veremos la siguiente imagen
mi cuenta de GMAIL
Como vemos en la imagen de arriba (resaltado en rojo), debemos hacer clic en el apartado de «Inicio de sesión y seguridad». Y allí nos desplazamos hasta la parte inferior y habilitamos/activamos la opción «Permitir el acceso de aplicaciones menos seguras», como en la imagen de abajo.
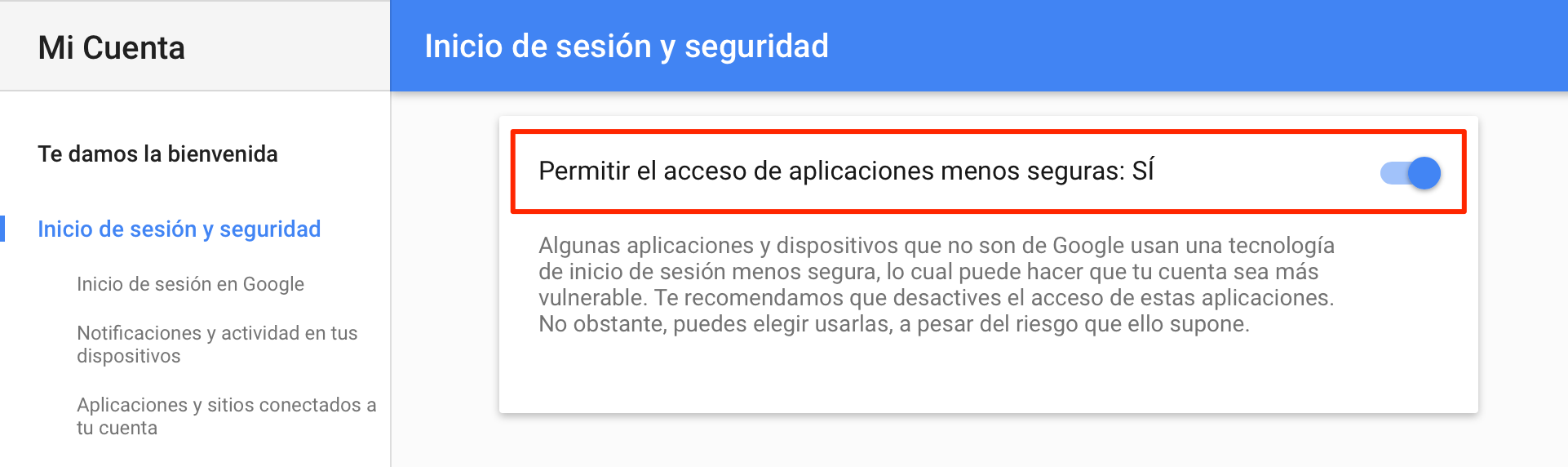
habilitar acceso de aplicaciones menos seguras
Hecho esto, vamos al programa, el cual hace uso de Java Mail. El programa es bastante sencillo consta de un fichero de configuración del siguiente tipo:
|
1 2 3 4 |
gmail.account=correo@gmail.com gmail.password=password emaildestinations=foo@domain1.com;bar@domain2.com;email@gmail.com attachmentfiles=path_to_file1;path_to_file2 |
gmail.account: La cuenta de GMAIL desde la cual enviaremos el correo electrónico.
gmail.password: El password de la cuenta de GMAIL desde la cual enviaremos el correo electrónico.
emaildestinations: Lista de direcciones de correo electrónico separadas por punto y coma («;») a donde será enviado el correo.
attachmentfiles: Lista de rutas donde están ubicados los ficheros a adjuntar separados por punto y coma («;»).
A continuación el programa Java encargado del envío del correo electrónico.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 |
package com.josedeveloper; import java.io.File; import java.io.IOException; import java.io.InputStream; import java.util.Properties; import javax.activation.DataHandler; import javax.activation.DataSource; import javax.activation.FileDataSource; import javax.mail.BodyPart; import javax.mail.Message; import javax.mail.MessagingException; import javax.mail.Multipart; import javax.mail.PasswordAuthentication; import javax.mail.Session; import javax.mail.Transport; import javax.mail.internet.InternetAddress; import javax.mail.internet.MimeBodyPart; import javax.mail.internet.MimeMessage; import javax.mail.internet.MimeMultipart; public class SendMail { public static void main(String[] args) throws IOException { Properties props = new Properties(); props.put("mail.smtp.host", "smtp.gmail.com"); props.put("mail.smtp.socketFactory.port", "465"); props.put("mail.smtp.socketFactory.class", "javax.net.ssl.SSLSocketFactory"); props.put("mail.smtp.auth", "true"); props.put("mail.smtp.port", "465"); String resourceName = "config.properties"; ClassLoader loader = Thread.currentThread().getContextClassLoader(); Properties config = new Properties(); try(InputStream resourceStream = loader.getResourceAsStream(resourceName)) { config.load(resourceStream); } final String gmailAccount = config.getProperty("gmail.account"); final String gmailPassword = config.getProperty("gmail.password"); final String[] emailDestinations = config.getProperty("emaildestinations").split(";"); final String[] attachmentFiles = config.getProperty("attachmentfiles").split(";"); Session session = Session.getDefaultInstance(props, new javax.mail.Authenticator() { protected PasswordAuthentication getPasswordAuthentication() { return new PasswordAuthentication(gmailAccount,gmailPassword); } }); try { Message message = new MimeMessage(session); message.setFrom(new InternetAddress(gmailAccount)); for (String emailDestination : emailDestinations) { message.addRecipients(Message.RecipientType.TO, InternetAddress.parse(emailDestination)); } message.setSubject("Email Subject - Asunto del correo electronico"); BodyPart messageBodyPart = new MimeBodyPart(); messageBodyPart.setText("Email text Body - Texto o cuerpo del correo electronico"); Multipart multipart = new MimeMultipart(); for (String attachmentFile : attachmentFiles) { addAttachment(multipart, attachmentFile); } //Setting email text message multipart.addBodyPart(messageBodyPart); //set the attachments to the email message.setContent(multipart); Transport.send(message); System.out.println("Correo enviado"); } catch (MessagingException e) { throw new RuntimeException(e); } } private static void addAttachment(Multipart multipart, String filePath) throws MessagingException { File file = new File(filePath); DataSource source = new FileDataSource(file); BodyPart messageBodyPart = new MimeBodyPart(); messageBodyPart.setDataHandler(new DataHandler(source)); messageBodyPart.setFileName(file.getName()); multipart.addBodyPart(messageBodyPart); } } |
El ejemplo es bastante sencillo, pero nos muestra como indicar el asunto del email, el texto del mensaje así como adjuntar ficheros. Espero que les pueda ser de utilidad. Aquí el enlace al proyecto en Github.